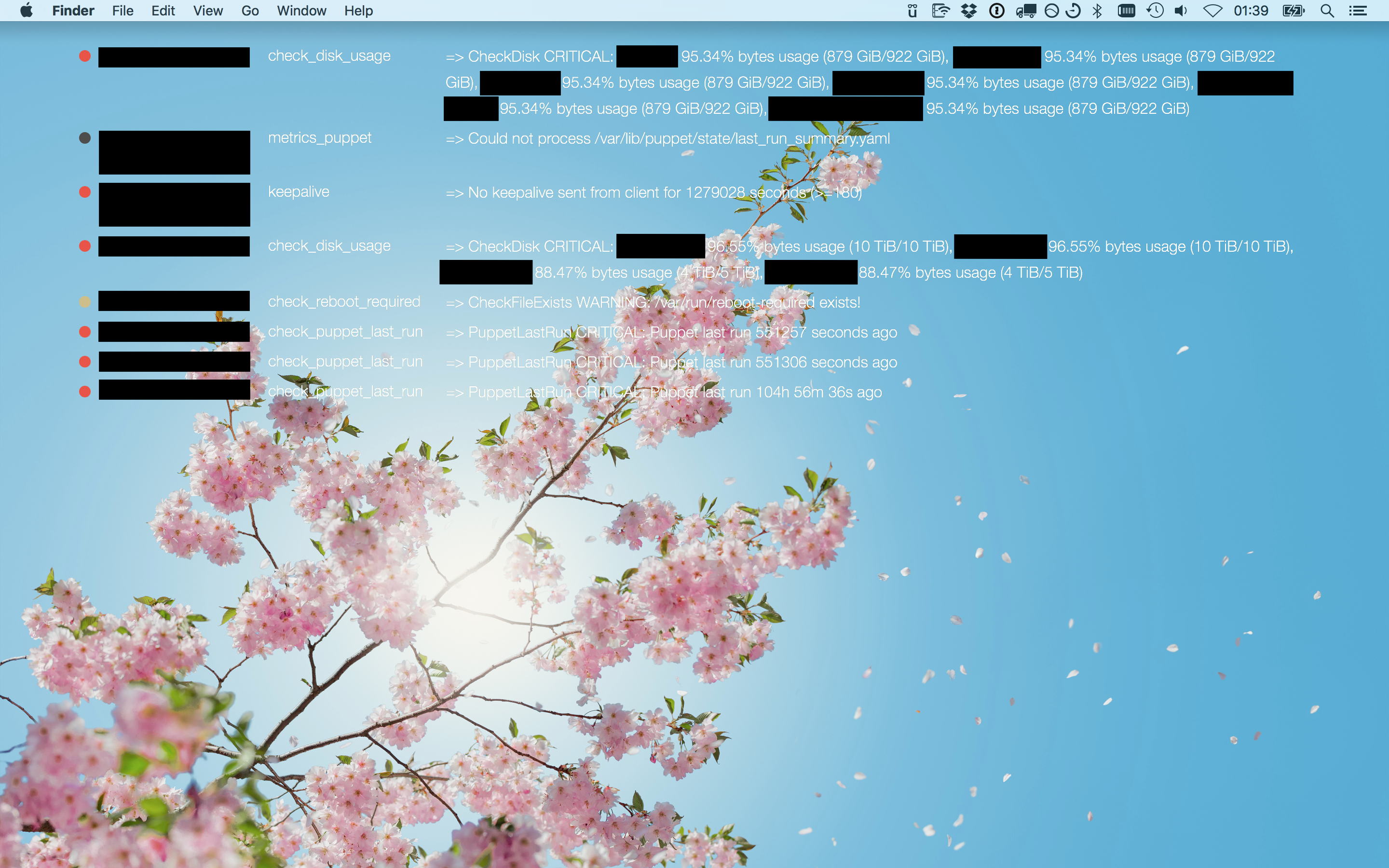
I’ve already written once before that I like working with GitLab’s Continuous Integration (CI) technology. I’ve now had the chance to set up a project for one of our research teams using GitLab CI and it’s been a true success.
- This post was updated once (2016-08-28)
In short: We’re using GitLab CI to build and deploy a C++ library. We are downloading its dependencies, compiling them, compiling our library, creating Debian packages and installing them on the 6 servers we use for heavy-duty computing.
- This writeup contains notes on
vagrant, docker, gitlab-ci-multi-runner, fpm and cmake.
- I worked with Christian Mostegel and Markus Rumpler on this project.
Sections:
- Preparation
- Automatic Building
- Docker
- GitLab Runners
- GitLab CI
- GitLab CI: Details on Jobs
- GitLab CI: Details on Script
- GitLab CI: Details on FPM
- GitLab CI: Building the library
- Automatic Deployment
- Deployment: Sudoers
- Deployment: Jobs
- Summary
- What went wrong
Preparation
We already had a GitLab instance that I’m very fond of and some knowledge on how to set up automatic builds from previous projects.
First we needed to verify that the library would build at all under the given conditions (Debian Jessie, amd64, specified dependencies). To ensure this, we used Vagrant to create a virtual machine whose configuration in terms of installed development packages was similar our local environment.
Using this VM as testbed we prepared the download and build of the dependencies of which Debian packages didn’t readily exist in the configuration the researchers specified by writing a simple shell script.
Next we tried to build the library in this machine and added the required packages bit by bit after verifying what was really needed to build. These packages were collected since they would be the base of the Docker image we would build later to speed up the CI runs.
The final result of our preparation was a Vagrantfile which set up the machine and compiled as well as packaged our library with a simple vagrant up.
Automatic Building
Docker
The next step was to build the Docker image. This was fairly simple given that we already relied on two other automatically built Docker images from previous projects. We created another repository on GitHub to link with Docker Hub and waited for everything to be built (of course it didn’t work perfectly and there was quite a lot of iteration in about every step I mention).
We typically build our images on top of buildpack-deps given that it’s an official, somewhat slim, development oriented image. Here’s the Dockerfile currently in use during writing this article:
FROM buildpack-deps:jessie
MAINTAINER Alexander Skiba <alexander.skiba@icg.tugraz.at>
ENV DEBIAN_FRONTEND noninteractive
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential \
cmake \
freeglut3 \
freeglut3-dev \
gcc \
git \
g++ \
libatlas-dev \
libatlas-base-dev \
libboost-all-dev \
libblas-dev \
libcgal-dev \
libdevil-dev \
libeigen3-dev \
libexiv2-dev \
libglew-dev \
libgoogle-glog-dev \
liblapack-dev \
liblas-dev \
liblas-c-dev \
libpcl-dev \
libproj-dev \
libprotobuf-dev \
libqglviewer-dev \
libsuitesparse-dev \
libtclap-dev \
libtinyxml-dev \
mlocate \
ruby \
ruby-dev \
unzip \
wget \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/* \
&& gem install --no-rdoc --no-ri fpm
GitLab Runners
After the image was built, we set up GitLab runners on each of our computing machines so that we could also use their cores and memory to speed up building the project itself. On each of these machines two runners were configured - one with shell, the other with docker as executor. Here’s an example /etc/gitlab-runner/config.toml from production.
concurrent = 1
[[runners]]
name = "example1"
url = "REDACTED"
token = "REDACTED"
executor = "docker"
[runners.docker]
tls_verify = false
image = "icgoperations/3dlib"
privileged = false
disable_cache = false
volumes = ["/cache"]
[runners.cache]
Insecure = false
[[runners]]
name = "example1-shell"
url = "REDACTED"
token = "REDACTED"
executor = "shell"
[runners.ssh]
[runners.docker]
tls_verify = false
image = ""
privileged = false
disable_cache = false
[runners.parallels]
base_name = ""
disable_snapshots = false
[runners.virtualbox]
base_name = ""
disable_snapshots = false
[runners.cache]
Insecure = false
GitLab CI
Next we converted the previously written Bash script into the format needed by .gitlab-ci.yml. In the *-build jobs we download, build and package our dependencies.
stages:
- dependencies
- build
- deploy
ceres-build:
stage: dependencies
script:
- export I3D_CERES_VERSION=1.11.0
- wget --quiet https://github.com/ceres-solver/ceres-solver/archive/$I3D_CERES_VERSION.tar.gz
- mkdir ceres-source ceres-build ceres-install
- tar xvfz $I3D_CERES_VERSION.tar.gz -C ceres-source --strip-components=1
- cmake -Bceres-build -Hceres-source
- make -j$(nproc) -C ceres-build
- make -C ceres-build install DESTDIR=../ceres-install
- bash .gitlab_build_files/build_ceres_debian_pkg.sh
artifacts:
paths:
- i3d-ceres_*_amd64.deb
tags:
- linux,debian-jessie
opencv-build:
stage: dependencies
script:
- export I3D_OPENCV_VERSION=2.4.10
- wget --quiet https://github.com/Itseez/opencv/archive/$I3D_OPENCV_VERSION.tar.gz
- mkdir opencv-source opencv-build opencv-install
- tar xvfz $I3D_OPENCV_VERSION.tar.gz -C opencv-source --strip-components=1
- cmake -Bopencv-build -Hopencv-source -DCMAKE_BUILD_TYPE=RELEASE -DBUILD_DOCS=OFF -DBUILD_PERF_TESTS=OFF -DBUILD_JPEG=ON -DBUILD_PNG=ON -DBUILD_TIFF=ON -DBUILD_opencv_gpu=OFF -DWITH_FFMPEG=OFF
- make -j$(nproc) -C opencv-build
- make -C opencv-build install DESTDIR=../opencv-install
- bash .gitlab_build_files/build_opencv_debian_pkg.sh
artifacts:
paths:
- i3d-opencv_*_amd64.deb
tags:
- linux,debian-jessie
GitLab CI: Details on Jobs
Since this can be a little overwhelming, I’d like to explain one section in detail. I’ll write GitLab terms italicized.
ceres-build:
stage: dependencies
script:
- export I3D_CERES_VERSION=1.11.0
- wget --quiet https://github.com/ceres-solver/ceres-solver/archive/$I3D_CERES_VERSION.tar.gz
- mkdir ceres-source ceres-build ceres-install
- tar xvfz $I3D_CERES_VERSION.tar.gz -C ceres-source --strip-components=1
- cmake -Bceres-build -Hceres-source
- make -j$(nproc) -C ceres-build
- make -C ceres-build install DESTDIR=../ceres-install
- bash .gitlab_build_files/build_ceres_debian_pkg.sh
artifacts:
paths:
- i3d-ceres_*_amd64.deb
tags:
- linux,debian-jessie
Here ceres-build is the unique name for the job (one step of a build process) - it’s the identifier of one build unit.
The stage describes where in the build pipeline (all jobs combined for one project) you want this job to be executed. The default stages are build => test => deploy. We defined our stages to be dependencies => build => deploy before for this project, so ceres-build is executed in the first stage. Jobs in the same stage will be run in parallel, if possible (e.g. you have more than one runner, or at least one runner set to use concurrent builds).
After a build has finished running, you may choose not to discard all files automatically when using Docker and opt to keep some selected ones. This is done by specifying artifacts. We specified that all files matching i3d-ceres_*_amd64.deb shall be kept - a matching example would be i3d-ceres_1.11.0_amd64.deb. We also experimented with the newly released option of automatically expiring artifacts after a given amount of time has passed but were not convinced this was mature enough just yet.
The tags section helps GitLab Runner decide which machine to run the job on. We tagged our runners with linux and debian-jessie before. By using the same tags in .gitlab-ci.yml we make sure that one of the prepared machines is used.
The script section consists of a list of shell commands to run for the build. If one exists with a different code than 0, the build is assumed to have failed, otherwise it’s good.
GitLab CI: Details on Script
# Use an environment variable to avoid hardcoding the version number
export I3D_CERES_VERSION=1.11.0
# Download the given release directly from the GitHub project releases
wget --quiet https://github.com/ceres-solver/ceres-solver/archive/$I3D_CERES_VERSION.tar.gz
# Prepare the directories we are going to be working in
mkdir ceres-source ceres-build ceres-install
# Unpack the archive and strip the folder containing the version number
tar xvfz $I3D_CERES_VERSION.tar.gz -C ceres-source --strip-components=1
# Configure Makefiles with given Build directory and Home (source) directory
cmake -Bceres-build -Hceres-source
# Build the project with the same number of threads as the machine has cores
make -j$(nproc) -C ceres-build
# "Install" the finished product locally into a given directory
make -C ceres-build install DESTDIR=../ceres-install
# Package the result with FPM (see FPM section)
bash .gitlab_build_files/build_ceres_debian_pkg.sh
GitLab CI: Details on FPM
As you might have already seen, I use long option names where possible to improve readability. In the following fpm command there are some short names however.
t is for type of targets is for type of sourceC is for source directory
You can find even more parameters in the fpm wiki.
#! /usr/bin/env bash
fpm \
-t deb \
-s dir \
-C ceres-install \
--name "i3d-ceres" \
--version $I3D_CERES_VERSION \
--license "BSD" \
--vendor "ICG TU Graz" \
--category "devel" \
--architecture "amd64" \
--maintainer "Aerial Vision Group <aerial@icg.tugraz.at>" \
--url "https://aerial.icg.tugraz.at/" \
--description "Compiled Ceres solver for i3d library" \
--depends cmake \
--depends libatlas-dev \
--depends libatlas-base-dev \
--depends libblas-dev \
--depends libeigen3-dev \
--depends libgoogle-glog-dev \
--depends liblapack-dev \
--depends libsuitesparse-dev \
--verbose \
.
After running FPM we have a nice, installable Debian package.
GitLab CI: Building the library
While building our own library is similar to the previously shown build, there are some differences worth mentioning.
- There is no need to download/fetch/checkout the source, GitLab Runner already does that automatically.
- The version which is later used for building the package includes the current date, time and the commit hash (example:
2016-07-10~1138.ea246ba) This ensures that the package version is both ever increasing and easily resolved into the source commit.
- We install the
.deb packages built in the previous stage. This is simple since GitLab CI makes artifacts of the previous stage available to the current stage automatically. Notice we also avoid specifying a version number by using a wildcard.
- While I prefer not to jump around with
cd during the build process and suggest to use flags instead, we had some trouble making that work with our library; so the cd statements stuck around.
icg3-build:
stage: build
script:
- export I3D_CORE_VERSION="$(date +%Y-%m-%d~%H%M)"."$(git rev-parse --short HEAD)"
- dpkg -i i3d-*.deb
- mkdir icg3d-build icg3d-install
- cd icg3d-build
- cmake -DUSE_CUDA=OFF -DAPP_SFM=OFF -DWITH_CGAL=ON -DWITH_QGL_VIEWER=ON -DWITH_QT=ON -DCORE_WITH_LAS=ON ..
- cd ..
- make -j$(nproc) -C icg3d-build/ICG_3DLib
- make -C icg3d-build/ICG_3DLib install DESTDIR=../../icg3d-install
- bash .gitlab_build_files/build_icg3d_debian_pkg.sh
artifacts:
paths:
- i3d-core_*_amd64.deb
tags:
- linux,debian-jessie
Automatic Deployment
Automatic deployment was a greater issue than automatic building due to security and infrastructure considerations.
Since we already used Puppet, one idea was to use Puppet to ensure => latest on the packages we were building ourselves. However, the apt provider needs a repository and we were not sure the dpkg provider supported versioned packages and using latest. In order to use our repository we would have had to set it up to automatically sign new packages. Furthermore we would’ve had to run apt-get update against every server on every machine virtually all the time which is bad practice since we’re not using an Apt Proxy or similar.
Another idea was to have locally scheduled execution via cron but that amounted to the same thing in my opinion.
Essentially I disliked any solution based on polling since this meant additional waiting time for the researchers with each build. When doing everything via the GitLab CI system, they would be able to configure notifications when all servers have received the newest build.
Deployment: Sudoers
However, to install something one needs sudo rights. Essentially, one would have to configure a special /etc/sudoers.d entry for gitlab-runner to be able to install the packages that we build previously and store with the artifacts feature. The required entry looked like this for our machines:
gitlab-runner machine[1-6]= NOPASSWD: /usr/bin/dpkg -i i3d-core_*_amd64.deb i3d-opencv_*_amd64.deb i3d-ceres_*_amd64.deb
For user gitlab-runner allow the command /usr/bin/dpkg -i i3d-core_*_amd64.deb i3d-opencv_*_amd64.deb i3d-ceres_*_amd64.deb on the machines machine[1-6] without asking for a password.
Additonally the shell runners are private runners and must be explicitly whitelisted by an admin or the owner for use on other projects. (read: should we get another project which needs automatic deployment)
Deployment: Jobs
Deployment jobs at the ICG work by specifying the host to which one needs to deploy as tag. In case something unstable hits a development branch, we only deploy the master branch. However, compilation and packaging is enabled for all branches. If needed, one could download those package via the GitLab web interface. The unfortunate side-effect of this is that the approch scales really, really bad. We have this section 6 times in own CI file - once for each machine we deploy to.
deploy-machine1:
stage: deploy
script:
- sudo dpkg -i i3d-core_*_amd64.deb i3d-opencv_*_amd64.deb i3d-ceres_*_amd64.deb
tags:
- machine1
only:
- master
Summary
It is possible to build a pipeline which gets, compiles and packages dependencies, builds and packages your own C/C++ project and deploys it to multiple machines with GitLab CI. In our case, the whole process takes about 8 minutes or less, depending on which machines are picked for the build process and if a new version of the Docker image has been build and must be fetched first.
If you had the need to distribute to more machines but immediate feedback is not that important, uploading to the import folder of an automated Debian repository (e.g. Reprepro) should scale really well.
Building for other linux platforms (e.g. Ubuntu instead of Debian) should be easily solved via Docker images, while different architectures (e.g. i386 instead of amd64) would require another host or a VM. The build process could even be modified to build for Windows or macOS hosts with prepared VMs or hosts. We currently don’t have any experience with either, though.
Update (2016-08-28)
Since GitLab 8.11 has solved our issues with artifact expiry, we’ve now enabled automatic expiration with success and are quite satisfied with the result.
It is as easy as adding one section to a job.
icg3-build:
stage: build
script:
- export I3D_CORE_VERSION="$(date +%Y-%m-%d~%H%M)"."$(git rev-parse --short HEAD)"
- dpkg -i i3d-*.deb
- mkdir icg3d-build icg3d-install
- cd icg3d-build
- cmake -DUSE_CUDA=OFF -DAPP_SFM=OFF -DWITH_CGAL=ON -DWITH_QGL_VIEWER=ON -DWITH_QT=ON -DCORE_WITH_LAS=ON ..
- cd ..
- make -j$(nproc) -C icg3d-build/ICG_3DLib
- make -C icg3d-build/ICG_3DLib install DESTDIR=../../icg3d-install
- bash .gitlab_build_files/build_icg3d_debian_pkg.sh
artifacts:
paths:
- i3d-core_*_amd64.deb
tags:
- linux,debian-jessie
+ expire_in: 1 month
What went wrong
As I said, not everything went right from the beginning. I thought it might be interesting to add some notes on possible issues.
- The
.debs ended up empty. => The source directory was empty to begin with since make install had been forgotten.
- The
.debs were extraordinarily large. => The wrong source directory was chosen - probably the *_build folder instead of *_install.
- Cmake didn’t pick up the Build/Home directory and refused to run. => There mustn’t be any spaces between
-B and the target directory.
- Cmake refused to acknowledge options. => There mustn’t be any spaces between
-D and the option; there must be a = between the option and its value.
- Jobs were picked up by the wrong runner and failed. => Improve labeling of different private and public runners so that e.g.
linux & debian-jessie are only labels of the Docker runner, not the Shell one; configure runners as private runners to not pick up unlabeled jobs.